
티스토리 뷰
주어지는 string을 띄어쓰기로 split한 후, 단순히 뒤집는 작업 전에, 태그를 인식해서 거기서는 뒤집는 작업이 일어나지 않게 해야한다.
1. tag 찾기
indexOf 메서드를 사용한다. 그렇지만, 한 단어에 tag가 여러개 나올 수도 있는 데 반해 indexOf는 단 하나만을 반환한다.
따라서 단순히 쓰기보단 두번째 parameter를 이용해야 한다.
이렇게 하는데... 이상하게 태그 분리가 안되는 문제가 계속 발생한다.
근데 애초에 문제는...'주어지는 string을 띄어쓰기로 split한 후' 이게 문제였다. 태그 안 띄어쓰기까지 맨 처음에 분리해버린거였음... 아오!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! 이거때문에 1시간을...
즉, 애초에 split부터 틀어진 것이었다...

split() 관련 MDN 문서를 찾아보다 발견한 것.
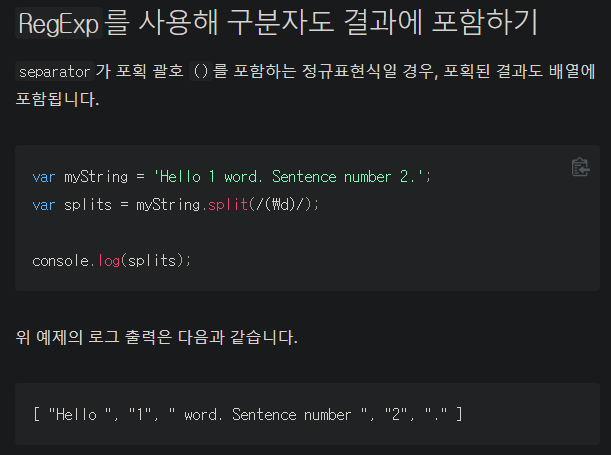
이런게 있었던가...????
https://hamait.tistory.com/342 여기 블로그를 통해 파악했다.
즉 내가 대충 짤 정규표현식은...
/(꺽쇠와 내부의 알파벳소문자와 띄어쓰기|알파벳소문자or숫자인 모든것)/g 인것이다.
꺽쇠는 <>로, 내부 문자와 띄어쓰기는 [/w ]로 가능하다.
근데, /w는 알파벳, 숫자, _를 포함하기떄문에 엄밀히 말하면 틀리다. 정확하게 문제에서는 '<'와 '>' 사이에는 알파벳 소문자와 공백만 있다. 라고 했다.
따라서 [a-z ]가 더 정확하겠음! 저렇게만 쓰면 단일문자이기때문에 +를 뒤에 붙여서 반복된다는 표현까지 해준다.
<[a-z ]+> 가 앞의 식이 되겠다.

이젠 알파벳소문자or숫자인 모든 것이다. 범위이기때문에 [ ] 안에 a-z와 0-9를 넣는다.
[a-z0-9]에다가 여러문자이기 때문에 +를 붙여서 완성한다.

훌륭하게 구분한다! 이제 실제로 코드에 넣어봤다.

생각해보니, 단어 간 띄어쓰기도 저장할 필요가 있었다. 그래서 정규표현식을 다시 한 번 수정했다.
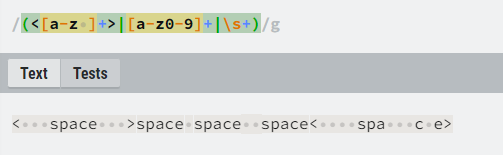

띄어쓰기를 포함해서 모두 구분하고있다. 이젠 정말 쉬운 일만 남았다.
그저 문자 맨 앞을 검사해서 문자라면 뒤집고, 아니라면 그냥 join해주면 되는 것이다.
문자 검사는 앞에서 배운 정규표현식을 또 활용하면 된다.
const fs = require("fs");
const filePath = process.platform === "linux" ? "/dev/stdin" : "./input.txt";
let inputChartext = fs.readFileSync(filePath).toString();
solution(inputChartext);
function solution(inputText) {
const seperator = /(<[a-z ]+>|[a-z0-9]+|\s)/g;
const isChar = /[a-z0-9]/;
let stringArray = inputText.match(seperator);
for (index in stringArray) {
if (isChar.test(stringArray[index].charAt(0))) {
stringArray[index] = stringArray[index].split("").reverse().join("");
}
}
console.log(stringArray.join(""));
}배운것 : 정규표현식
정규표현식을 익히고 실제로 써봤다는 점에서 정말 뿌듯했다.
사용이 정말 편하기도 해서 자주 써버릇해보려한다.

'■ 알고리즘 > ◻ 백준' 카테고리의 다른 글
| [C++] 1193번: 분수찾기 (0) | 2022.10.23 |
|---|---|
| [Python]10799번: 쇠막대기 (0) | 2022.08.12 |
| [Nodejs]10866번: 덱 (0) | 2022.08.03 |
| [Nodejs]1158번: 요세푸스 문제 (0) | 2022.08.03 |
| [Nodejs]10845번: 큐 (0) | 2022.08.02 |